深度解析 神經網絡圖像識別技術的演進與網絡層數的關鍵影響
神經網絡驅動的圖像識別技術已成為人工智能領域最具突破性的進展之一。從人臉識別、自動駕駛到醫療影像分析,這項技術正以前所未有的速度重塑各行各業。其核心在于模擬人腦神經元連接方式的計算模型,通過多層次的數據處理,使計算機能夠從原始像素中“理解”并分類圖像內容。
神經網絡的層數:模型深度的核心指標
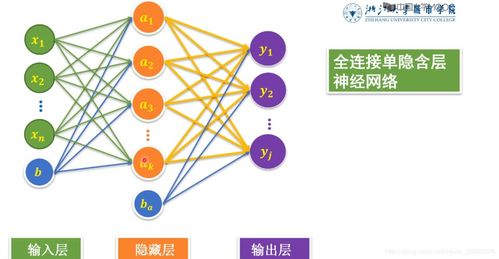
神經網絡的“層數”是衡量其復雜性與能力的關鍵維度,通常指網絡中的隱藏層數量。一個基礎的神經網絡包含輸入層、若干隱藏層和輸出層。
1. 淺層網絡與深層網絡的差異
- 淺層網絡(如傳統的感知機):通常僅有1-2個隱藏層。它們擅長學習簡單的、線性的特征映射,但在處理如圖像這類高度非線性、結構復雜的數據時,表達能力有限。
- 深層網絡(即深度學習模型):隱藏層數量顯著增加,可達數十甚至數百層(如ResNet、DenseNet)。每一層都能自動學習并提取不同抽象級別的特征——底層識別邊緣、色彩等基礎元素,中層組合成紋理、部件,高層則整合為完整的物體或場景。這種分層特征提取機制,正是其強大識別能力的源泉。
2. 如何“看”網絡層數及其意義
- 結構可視化:通過模型架構圖(如使用TensorBoard、Netron等工具)可直觀看到層與層之間的連接關系與數量。
- 性能影響:增加層數通常能提升模型的表現力,使其能學習更復雜的模式,但這并非無止境。層數過多可能導致:
- 梯度消失/爆炸:誤差在反向傳播過程中逐層傳遞時可能衰減或激增,使訓練變得極其困難。
- 過擬合:模型過度記憶訓練數據中的噪聲,導致在新數據上泛化能力下降。
- 計算成本飆升:需要更多的計算資源與時間。
- 現代解決方案:為了克服深度網絡的訓練難題,研究者引入了殘差連接(ResNet)、批量歸一化、深度可分離卷積等創新技術,使數百層的網絡也能穩定、高效地訓練。
網絡技術的研究前沿與挑戰
當前研究正從單純追求“更深”的網絡,轉向構建“更智能”的結構:
- 輕量化與效率:在移動設備、嵌入式系統上部署模型的需求,催生了MobileNet、ShuffleNet等輕量級架構。它們通過深度可分離卷積等技術,在保持精度的同時大幅減少參數與計算量。
- 神經架構搜索(NAS):自動化機器學習的重要分支,利用算法自動搜索最優的網絡層數、連接方式等超參數,旨在超越人工設計的架構,如EfficientNet系列模型便是NAS的杰出代表。
- 可解釋性與魯棒性:研究者正致力于揭示“黑箱”決策過程,增強模型對抗對抗性攻擊的能力,并確保其在多樣、真實場景下的可靠性。
- 跨模態與自監督學習:結合文本、聲音等多模態數據訓練,以及利用大量無標簽數據通過自監督進行預訓練,正推動圖像識別走向更通用的視覺理解。
結論
神經網絡的層數不僅是模型復雜度的標尺,更是其智能水平的體現。從淺層到深層的演進,標志著圖像識別技術從“感知邊緣”到“理解場景”的質的飛躍。未來的研究將更注重效率、魯棒性與通用性的平衡,推動這項技術向著更強大、更可信、更普惠的方向持續發展。理解層數背后的原理與權衡,是有效應用和推進該領域研究的重要基石。
如若轉載,請注明出處:http://www.bobidh.cc/product/26.html
更新時間:2026-05-12 11:05:47